
2022년 프롬프트 엔지니어링이 주목받기 시작했습니다. 2024년에는 컨텍스트 엔지니어링이 그 자리를 이어받았고, 2026년에는 하네스 엔지니어링이라는 개념이 업계에 자리 잡고 있습니다. 3~5년 사이에 핵심 관심사가 세 번 바뀌었습니다.
이 흐름을 새로운 현상으로 볼 수도 있지만, 소프트웨어 엔지니어링의 역사를 알고 있다면 익숙한 패턴입니다. AI 엔지니어링은 소프트웨어 엔지니어링 60년이 걸어온 길을 압축해서 따라가고 있는 것 처럼 보입니다. 그 계단을 우리는 3~5년 만에 다시 오르고 있습니다.
이 글에서는 두 흐름을 살펴보고, 무엇이 같고 무엇이 다른지, 그리고 의미하는 바가 뭔지를 정리해 보고자 합니다.
목 차
익숙한 풍경, 빨라진 속도
최근 3~4년 사이 AI 엔지니어링에 등장한 용어를 시간순으로 늘어놓으면 이렇습니다.
- 프롬프트 엔지니어링 (2022년부터): 어떻게 요청할 것인가?
- 컨텍스트 엔지니어링 (2024년부터): 어떤 정보(맥락)을 함께 전달할 것인가?
- 하네스 엔지니어링 (2026년부터): 어떤 환경에서 실행할 것인가?
새 용어가 등장할 때마다 이전 개념을 대체한다는 분위기가 함께 따라옵니다. 하지만 소프트웨어 역사를 돌아보면 같은 패턴은 늘 반복됩니다. 어셈블리에서 C로, C에서 객체지향으로, 객체지향에서 마이크로서비스로 넘어올 때마다 “이전 방식은 끝났다”는 말이 있었습니다. 하지만 그 모든 것은 사라지지 않았습니다. 추상화의 한 축으로 자리 잡았을 뿐입니다.
AI 엔지니어링도 같은 길을 갑니다. 다만 속도가 빠를 뿐입니다.
다섯번의 추상화 단계
소프트웨어 엔지니어링이 60년 이상에 걸쳐 오른 추상화의 계단을, AI 엔지니어링은 3~5년 만에 압축적으로 따라가고 있습니다. 다섯 단계로 정리해보겠습니다.
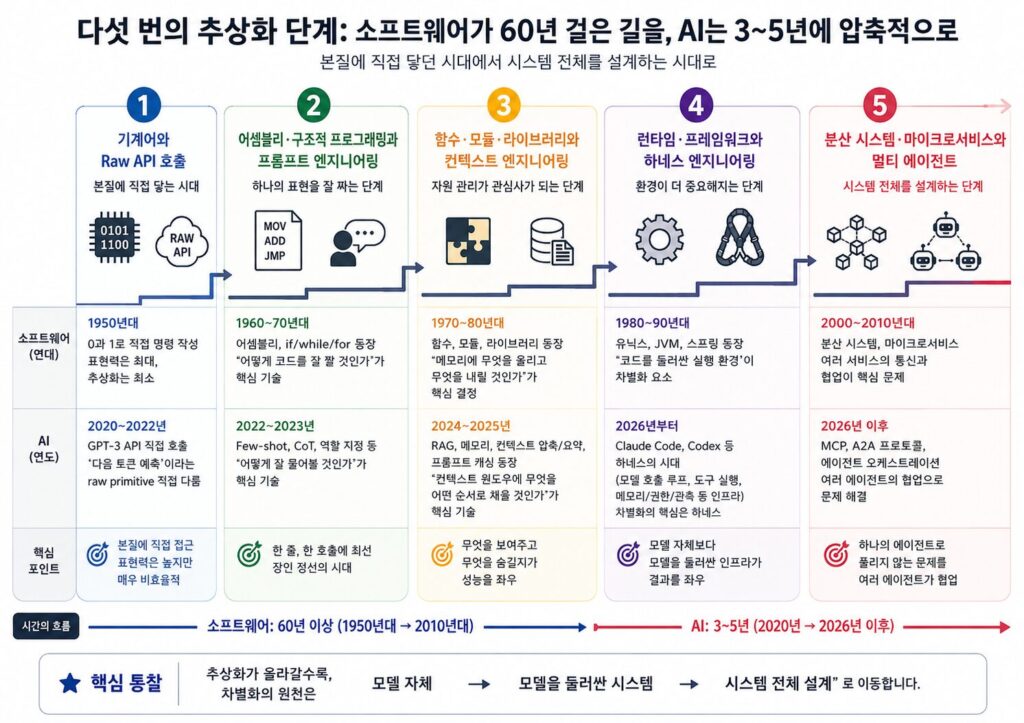
[1단계] 기계어와 Raw API 호출 — 본질에 직접 닿는 시대
소프트웨어 (1950년대): 0과 1로 직접 명령을 작성하던 시대. 한 줄 한 줄이 고된 노동이었습니다. 표현력은 최대지만 추상화는 최소였습니다.
AI (2020~2022년): GPT-3 API를 직접 호출하던 시기. “다음 토큰 예측”이라는 raw primitive를 직접 다뤄야 했습니다. 시스템 메시지도 없고, 도구 호출도 없던 시절입니다.
기술적으로는 매력적이지만 무척 비효율적이었습니다. 곧 누군가가 더 편한 표현 방식을 만들게 됩니다.
[2단계] 어셈블리·구조적 프로그래밍과 프롬프트 엔지니어링 — 하나의 표현을 잘 짜는 단계
소프트웨어 (1960~70년대): 어셈블리가 등장하고, 곧이어 if, while, for라는 구조화된 제어 흐름이 자리 잡았습니다. “어떻게 코드를 잘 짤 것인가”가 핵심 기술이었고, 코딩 기술 자체가 경쟁력이었습니다.
AI (2022~2023년): Few-shot, Chain-of-Thought, 역할 지정 같은 기법이 등장했습니다. “어떻게 잘 물어볼 것인가”가 핵심 기술이었고, 프롬프트를 잘 다루는 것 자체가 경쟁력이었습니다.
한 줄, 한 호출에 최선을 다하는 시기로, 장인 정신에 가까웠고, 곧 자동화와 표준화 압력을 받기 시작합니다.
[3단계] 함수·모듈·라이브러리와 컨텍스트 엔지니어링 — 자원 관리가 관심사가 되는 단계
소프트웨어 (1970~80년대): 함수, 모듈, 라이브러리가 등장했습니다. 코드 재사용과 변수 범위 관리가 핵심 기술이 됐습니다. “메모리에 무엇을 올리고 무엇을 스택에서 내릴 것인가”가 중요한 결정사항이었습니다.
AI (2024~2025년): RAG, 메모리 시스템, 컨텍스트 압축과 요약, 프롬프트 캐싱이 등장했습니다. “유한한 컨텍스트 윈도우에 무엇을 어떤 순서로 채울 것인가”가 핵심 기술이 됐습니다.
변수 범위와 컨텍스트 윈도우는 매우 유사한 문제를 다루고 있습니다. 무엇을 보여주고 무엇을 숨길지가 시스템 성능을 좌우합니다.
[4단계] 런타임·프레임워크와 하네스 엔지니어링 — 환경이 더 중요해지는 단계
소프트웨어 (1980~90년대): 유닉스, JVM, 스프링 같은 런타임과 프레임워크의 시대. 코드 자체보다 “코드를 둘러싼 실행 환경”이 차별화 요소가 됐습니다. 같은 자바 코드라도 어떤 JVM 위에서 도느냐가 결과를 갈랐습니다.
AI (2026년부터): Claude Code, Codex, OpenClaw 같은 하네스(harness)의 시대. Anthropic이 2026년 초 이 용어를 공식화했습니다. 모델을 둘러싼, 모델 자체를 제외한 모든 소프트웨어 인프라를 가리킵니다. 모델 호출 루프, 도구 실행, 컨텍스트와 메모리 관리, 권한과 안전 게이트, 관측과 로깅이 모두 여기에 포함됩니다.
LangChain의 Vivek Trivedy가 쓴 「The Anatomy of an Agent Harness」에 따르면, 모델은 그대로 두고 하네스만 바꿔서 TerminalBench 2.0에서 30위권 밖에 있던 순위를 5위까지 끌어올렸습니다. 2026년 3월 유출된 Claude Code의 소스 코드는 1,906개 파일, 약 51만 2천 줄 규모였는데, 이 전체가 모델을 감싸는 하네스였습니다.
여전히 모델의 능력이 중요하지만, 진짜 차별화는 하네스에서 나옵니다.
[5단계] 분산 시스템·마이크로서비스와 멀티 에이전트 — 시스템 전체를 설계하는 단계
소프트웨어 (2000~2010년대): 분산 시스템, 마이크로서비스, 컨테이너 오케스트레이션의 시대. 하나의 프로세스가 잘 도는 것으로는 충분치 않게 됐습니다. 여러 서비스가 어떻게 통신하고 협업하느냐가 새로운 문제로 떠올랐습니다.
AI (2026년 이후): MCP, A2A 같은 에이전트 간 통신 프로토콜, 에이전트 오케스트레이션 플랫폼이 등장하기 시작했습니다. 하나의 에이전트로 풀리지 않는 문제를 여러 에이전트가 협업해서 풉니다.
아직은 초기 단계이나, 소프트웨어가 그러했듯이, 곧 표준 방식으로 자리 잡을 것입니다.
왜 같은 길을 가는가
이러한 상황이 우연일까요? 그렇지 않습니다. 계산(Computation)을 다루는 시스템이라면 누구나 마주하는 문제의 구조가 같기 때문입니다.
보통 다음의 네 가지 압박이 존재합니다.
첫째, 표현력과 추상화의 trade-off. 더 강력해지려면 더 낮은 수준을 직접 다뤄야 하고, 더 편해지려면 더 추상화해야 합니다. 영원한 계단 오르기입니다. 어셈블리에서 파이썬으로 가는 길과, Raw API 호출에서 하네스로 가는 길은 대상은 다르지만 같은 방법으로 문제를 풀고 있습니다.
둘째, 유한한 자원 관리. 메모리, 스택, 시간, 컨텍스트 윈도우, 모두 유한한 자원입니다. 그렇기 때문에 관리 기법이 필요하고, 그 기법이 곧 엔지니어링의 핵심이 됩니다. 메모리 크기와 컨텍스트 윈도우는 본질이 같은 문제입니다.
셋째, 코어 내부와 외부 환경과의 접점. 프로그램 내부는 결정적(Deterministic)이지만, 외부 세계(네트워크, 사용자 입력, 시간)는 비결정적(Non-deterministic)입니다. 그 접점에서 인터페이스 설계, 에러 처리, 안전성 문제가 발생합니다. AI에서도 마찬가지입니다. 다만 AI에서는 외부가 아니라 코어(LLM) 내부도 비결정적이라는 점이 다릅니다.
넷째, 개체에서 시스템으로의 확장. 하나가 잘 돌면, 여러 개를 어떻게 같이 돌릴지가 다음 문제가 됩니다. 분산 시스템과 멀티 에이전트의 사례가 이러한 상황을 잘 보여줍니다.
이렇게 유사한 압박이 존재한다면 그 해법도 같은 방향을 향하게 됩니다. AI도 결국 계산 시스템이고, 같은 문제를 마주하면 같은 해법을 찾아갑니다.
다만 다른 점도 있다
모든 것이 같지는 않습니다. 본질적인 차이가 셋 있습니다.
첫째, 속도. 소프트웨어가 60년에 걸쳐 오른 계단을 AI는 3~5년 만에 오릅니다. 학습 곡선이 매우 가파릅니다. 어셈블리에서 객체지향까지 가는 동안 소프트웨어 엔지니어는 한 세대를 준비할 시간이 있었지만, AI에서는 같은 기간 안에 자신이 쓰던 도구가 쉴새 없이 바뀝니다. 개인과 조직 모두 적응 속도 자체가 능력이 되는 시대입니다.
둘째, 비결정성이 코어 내부에 있다. 전통 소프트웨어에서는 결정적인 코어 위에 비결정적인 외부 세계가 얹혀 있었습니다. AI에서는 코어 자체(LLM)가 확률적입니다. 같은 입력에 다른 출력이 나오는 부품을 안고 시스템을 만드는 일은, 전통 소프트웨어 엔지니어링의 모든 원칙을 다시 검토하게 만듭니다. 테스트, 디버깅, 재현성, 에러 처리가 모두 새로 정의되어야 합니다. “이게 정상 동작인가?”를 판단하는 일이 더 이상 자명하지 않습니다.
셋째, 메타 능력의 등장. 소프트웨어 역사에서는 사람이 추상화의 계단을 한 단씩 올렸습니다. AI에서는 하네스가 자기 자신을 수정하기 시작했습니다. 메타 하네스(Meta-Harness) 또는 하네스 정렬(Harness Alignment)이라는 흐름이 그것입니다. AI 에이전트가 실행 기록을 읽고 자신의 환경, 즉 컨텍스트 관리 방식과 도구 호출 시점을 스스로 다시 작성합니다. 일부 연구에서는 이렇게 스스로를 수정하는 방식이 사람이 손으로 설계한 시스템을 능가하는 결과를 보이기 시작했습니다. Stanford IRIS Lab의 Meta-Harness 프로젝트는 Terminal-Bench 2.0에서 76.4% 통과율을 기록했습니다.
마지막 차이가 가장 의미심장합니다. 소프트웨어 60년 진화의 모든 단계는 사람이 도구를 만든 역사였습니다. AI에서는 도구가 도구를 만드는 단계가 이미 시작됐습니다.
다음 단계는 어디인가
소프트웨어 역사가 가르쳐주는 패턴이 있다면, 다음 단계도 어느 정도 예측할 수 있습니다. 네 가지 흐름을 짚어봅니다.
첫째, 표준화. 지금 난립하고 있는 각종 인터페이스들이 몇 개의 표준으로 모일 것입니다. MCP가 도구 통신의 표준으로 자리 잡아가는 것이 그 시작입니다. 소프트웨어에서 POSIX, HTTP, REST가 그랬듯이, AI에서도 핵심 인터페이스 몇 개가 살아남고 나머지는 호환 계층으로 남을 것입니다.
둘째, 운영(Ops)의 부상. DevOps가 소프트웨어에서 그랬듯, AgentOps가 별도 분야로 성장할 것 같습니다. 모델, 하네스, 컨텍스트의 버전 관리, 배포, 롤백, 모니터링이 자기만의 도구 체계를 갖게 될 것입니다. IDC 리서치에 따르면 엔터프라이즈 AI 에이전트 프로젝트(POC)의 88%가 프로덕션에 도달하지 못합니다. 이 수치는 운영 영역의 빈틈을 보여준다고 생각합니다.
셋째, 보안과 거버넌스. 인터넷 보안이 90년대 후반에 폭발했듯, AI 보안과 거버넌스가 다음 큰 산업이 될 것입니다. 에이전트가 자율적으로 도구를 쓰는 순간, 권한, 감사, 책임 추적의 문제가 모두 따라옵니다. 소프트웨어에서 한 세대를 거쳐 정립된 보안 best practice가 AI에서는 짧은 기간에 다시 짜일 것입니다.
넷째, 다시 한 단계 위. 시스템 엔지니어링 위에 또 새로운 추상화가 올 것입니다. 소프트웨어 역사에서 분산 시스템 위에 클라우드와 서버리스가 올라왔듯이, 멀티 에이전트 위에는 무엇이 올지 아직은 알 수 없습니다. 다만 그 다음 추상화가 등장하면, 또 누군가가 “지금까지의 모든 것은 죽었다”고 말할 것이라는 점만은 확실합니다. 그리고 그 말은 또 틀릴 것입니다.
맺음말
AI 시대는 새로운 시대인 동시에 익숙한 풍경입니다. 추상화의 계단을 오르는 일은 60년 전이나 지금이나 같은 엔지니어링의 본질입니다.
새 용어에 휘둘릴 필요는 없습니다. 무엇이 진짜 새로운 본질이고 무엇이 익숙한 패턴의 반복인지를 가려내는 것, 그것이 엔지니어의 시선입니다. 프롬프트 엔지니어링은 사라지지 않습니다. 어셈블리가 사라지지 않았듯이, 추상화의 한 축으로 자리 잡을 뿐입니다.
충분한 경험을 가진 엔지니어에게 AI 시대는 위기가 아니라 가장 흥미로운 시기입니다. 우리는 소프트웨어 60년의 진화를 압축해서 다시 살아보는 중입니다.
소프트웨어 역사는 재연되고 있습니다. 다만 이번에는 훨씬 빠르게.
ChulJoo Kim (김철주).
※ 참고문헌
- Vivek Trivedy, 「The Anatomy of an Agent Harness」, LangChain Blog, 2026년 3월 10일. https://blog.langchain.com/the-anatomy-of-an-agent-harness/
- Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, Chelsea Finn, 「Meta-Harness: End-to-End Optimization of Model Harnesses」, arXiv:2603.28052, 2026. https://arxiv.org/abs/2603.28052 (아티팩트: https://github.com/stanford-iris-lab/meta-harness-tbench2-artifact)
- IDC, 「CIO Playbook 2025: It’s Time for AI-nomics」 (commissioned by Lenovo), 2025년 2월. https://news.lenovo.com/pressroom/press-releases/cio-playbook-global-study-roi-ai-adoption/
- Grant Gross, 「88% of AI pilots fail to reach production — but that’s not all on IT」, CIO, 2025년 3월 25일. https://www.cio.com/article/3850763/88-of-ai-pilots-fail-to-reach-production-but-thats-not-all-on-it.html
ckarch.kr
© 2026
is licensed under
CC BY-NC-SA 4.0
![]()
![]()
![]()
![]()