지난 글에서는 가족의 주식 계좌 거래내역을 한곳에서 보기 위해, 그동안 수동으로 하던 작업들을 바이브 코딩을 이용해서 엑셀 기반 자동화 도구를 개발한 과정을 다뤘습니다. 가장 먼저 사람이 손으로 하던 일을 코드로 똑같이 재현한 첫 번째 버전(V1)을 만들고, 그 위에서 입력의 확장성(V2)과 GUI 지원(V3) 등을 점진적으로 확대했습니다. (1편 보기)
V3까지 오면서 가장 중요한 핵심 기능은 충분히 완성되었습니다. 현재까지 확인된 모든 증권사 파일을 입력으로 받아들여 정확한 통계를 만들어 낼 수 있게 되었습니다. 이제 이 기능을 여러 사람이 동시에 편하게 쓰는 서비스로 진화시킬 차례입니다.
다만 개인이 한 대의 PC에서 쓰던 도구를 여러 사람이 함께 쓰는 서비스로 만들려면, 새롭게 고려할 것들이 생깁니다.
- 여러 사람이 동시에 접근하고, 결과를 함께 본다.
- 누가 어떤 파일을 올렸는지 추적할 수 있어야 한다.
- PC든 태블릿이든, OS와 무관하게 같은 화면으로 쓸 수 있어야 한다.
- 데이터를 한곳에 모아 두고, 여러 방식으로 조회하고 꺼내 본다.
그래서 이번 글에서는 이 도구를 웹 서비스로 전환한 과정을 정리해 보려고 합니다.
목 차
- 구조 설계 — DB 기반 웹 서비스
- 데이터 관리 — 업로드와 import
- 화면 구성
- 사용자 권한 관리
- 개발 및 운영 방식
- MCP 도입 — AI가 직접 쓰는 도구
- AI와의 협업 방식
- 맺음말
구조 설계 — DB 기반 웹 서비스
웹서비스로 넘어가면서 가장 먼저 한 일은 구조 설계였습니다. 요구사항을 정리하고, 그것을 AI와 함께 PRD와 설계 문서로 작성한 뒤 구현에 들어갔습니다.
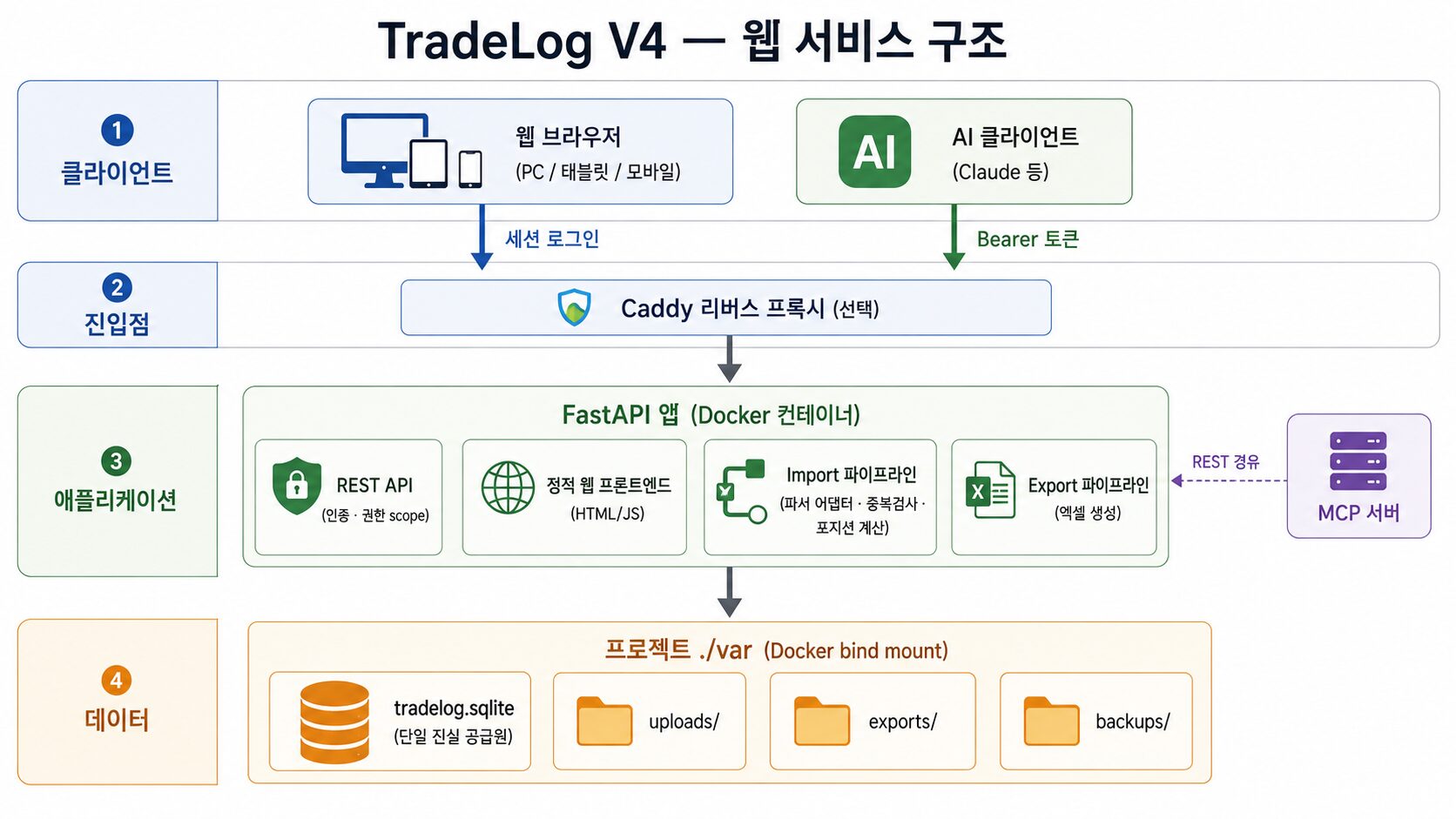
출력과 접근의 폭을 넓히려면, 먼저 데이터가 하나의 원본으로 모여 있어야 했습니다. V3까지 TradeLog의 가치는 잘 정리된 엑셀 결과물이었습니다. 하지만 여러 사람이 여러 방식으로 데이터를 보려면, 흩어진 파일이 아니라 모든 조회와 출력이 바라보는 하나의 기준 데이터, 즉 단일 진실 공급원(Single Source of Truth)이 필요했습니다. 그래서 기존 엑셀 파일 대신 서버의 DB가 원본이 되도록 하고, 엑셀은 필요하면 export해서 내려받을 수 있도록 했습니다.
전체 구조는 단순하게 잡았습니다. 제가 가지고 있는 Mac mini에서 Docker 기반으로 FastAPI 앱을 띄우고, RAW 파일을 웹에서 업로드하면 서버가 파싱해 SQLite DB에 저장하고, 웹 화면에서 조회와 통계를 제공하는 흐름입니다.
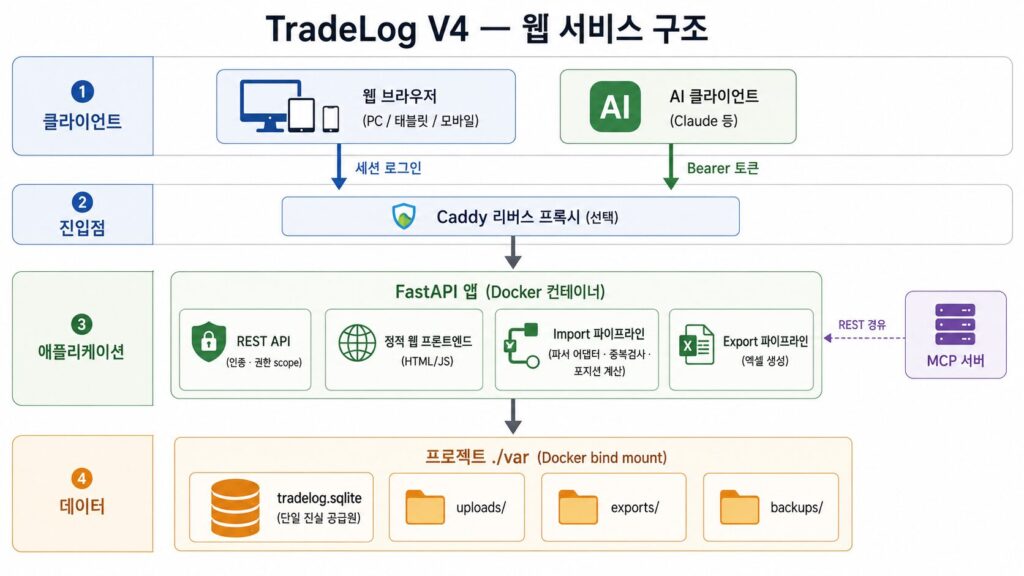
각 기술은 당연히 제가 먼저 선택을 한 건 아니고, AI와 상의를 해가면서 여러 선택지를 준비했고, 각 선택지의 장단점을 따져 가며 정했습니다. 구현 초기에는 MVP(Minimum Viable Product)를 목표로 화려함보다 단순함과 검증 속도 위주로 진행했습니다.
- DB: SQLite — 파일 하나로 구성되어 있어서 운영/관리가 쉽고, 운영자가 직접 다루기에도 편합니다. PostgreSQL도 고려는 했으나, 가족용 내부 서비스에는 운영 부담이 더 컸습니다. 다만 동시 접근이 늘어나면 락 관리가 필요해질 수 있다는 점은 참고사항으로 남겨 두었습니다.
- Frontend: 정적 HTML/CSS/JavaScript — React도 후보였지만, 빌드 도구 없이 화면과 API를 빠르게 바꿔 가며 검증하는 쪽을 선택했습니다. 대신 화면 상태가 복잡해지면
app.js가 비대해진다는 점을 알기에, 복잡도가 커지면 React 전환을 검토한다는 참고사항을 남겨 두었습니다. - 파서: V2 파서 활용 — V2가 이미 증권사별 예외를 검증된 형태로 처리하고 있었기 때문입니다. 이를 adapter로 감싸 DB 거래 행으로 변환하는 방식을 택했습니다. 파싱이라는 관심사를 따로 떼어 두면, 1편에서 만든 정답지를 그대로 재사용할 수 있습니다.
원본이 DB로 모였기 때문에, 백업을 할 때는 DB와 업로드한 엑셀 파일들이 대상이 됩니다.
데이터 관리 — 업로드와 import
구조를 잡은 뒤에는 데이터 흐름을 정리할 차례입니다. V3까지는 특정 폴더에 파일들을 넣어 두면 스크립트가 읽어 가던 방식이, 이제는 웹 업로드로 바뀌는 지점입니다.
업로드 파이프라인은 이렇게 동작합니다. 웹에서 소유주·증권사·계좌를 선택하고 RAW 파일을 선택해서 올리면, 서버가 파일을 저장하고 sha256 해시로 중복을 판별합니다. 새 파일이면 파서를 이용해서 정규화한 거래를 DB에 넣고, 인식하지 못한 항목은 경고로 따로 쌓습니다.
POST /api/uploads
→ 파일 저장 → sha256 계산
→ 같은 계좌에 같은 해시가 있으면 중복 skip
→ 새 파일이면 파싱 → 거래 저장 + 경고 저장 → 상태 갱신
중복 정책은 일단은 V2의 방식을 그대로 이어받았고, 필요 시 보강할 예정입니다. 같은 계좌에 같은 해시 파일이 이미 있으면 중복으로 보고 무시합니다. 파일명이 같아도 해시가 다르면 다른 파일로 간주합니다. 중복으로 건너뛴 파일도 이력을 보존하고, 나중에 다시 처리할 수 있는 여지를 남겼습니다.
기존 파싱 로직을 그대로 감싸 썼기 때문에, 동일한 데이터에 동일한 결과가 나오는 게 보장됩니다. 그래서 테스트 케이스들도 대부분 재활용할 수 있었습니다.
화면 구성
이제 사람이 실제로 보는 화면을 구성해야 합니다. 별다른 가이드 없이 화면을 구성해 달라고 했더니, 입력·조회·통계·설정 성격의 기능을 모두 한 화면에 보여주었습니다. 도저히 사용이 불가능했습니다.
우선 아래와 같이 4개의 화면으로 구성을 했습니다.
- 입력 — 소유주·증권사·계좌 등록, RAW 업로드
- 조회 — 거래내역 목록
- 통계 — 계좌별 통계
- 설정 — 사용자·그룹·업로드 내역·계좌 관리 등
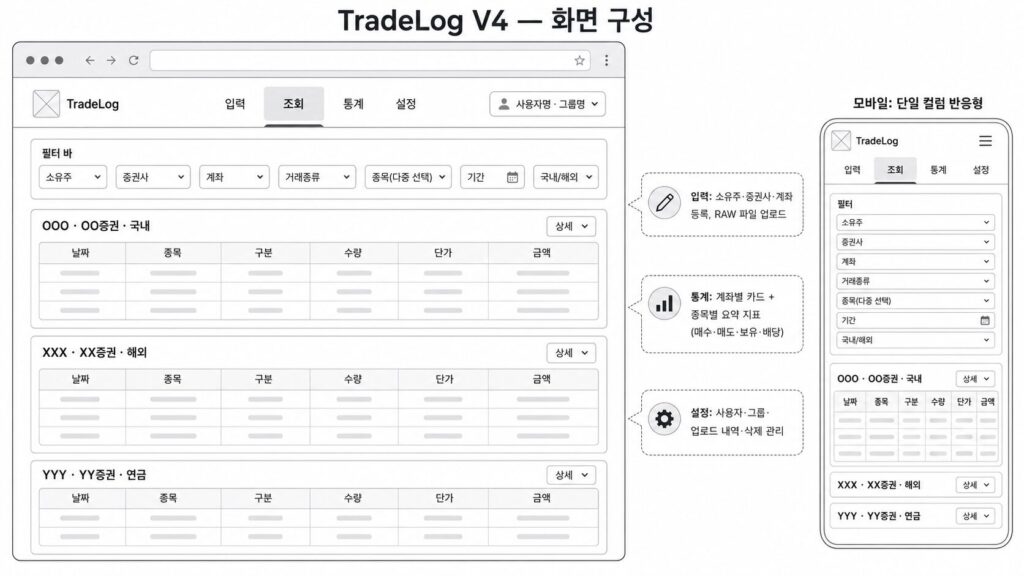
조회 화면은 단순한 표에서 출발했지만, 거래가 쌓이면서 다양한 관점을 표현할 필요가 있었습니다. 소유자·증권사·계좌·거래구분을 각각 다중 선택할 수 있도록 필터를 추가했습니다.
통계 화면을 구성하는 일은 좀 생각이 많이 필요했습니다. 처음에는 기존 엑셀 파일의 요약과 같이 한 줄에 압축해 보여줬는데, 정보는 정확했지만 사용성이 떨어지고 읽기 어려웠습니다. 결국 계좌 단위 카드로 묶고, 매수·매도·보유·배당·수수료·세금을 지표처럼 나눠 보여주는 형태로 정리했습니다. 그런데 통계를 정확히 맞추는 일이 생각보다 까다로웠습니다. 처음에는 조회할 때마다 매수·매도·배당을 집계하는 방식이었는데, 보유수량이 0인데 보유금액이 음수로 나오거나, 배당이 직전 보유 상태를 제대로 연결하지 못하는 문제가 생겼습니다. 기간 필터와 과거 거래의 뒤늦은 업로드까지 겹치면서 조회 시점 계산은 점점 복잡해졌습니다.
그래서 계산 시점을 변경하기로 했습니다. 조회할 때 계산을 하면 한꺼번에 부하가 걸리니, 파일 업로드나 삭제 같은 쓰기 작업이 발생할 때 거래별 누적 포지션(보유수량·보유단가·보유총액·매도차익)을 미리 계산해 거래 행에 저장하는 방식입니다. 과거 거래가 추가될 경우 해당 종목의 전체 이력을 다시 정렬해 재계산합니다. 이렇게 하니 조회 API가 단순해지고, 날짜 필터가 있어도 각 거래 시점의 보유값이 전체 이력 기준으로 유지되었고, 그제야 통계다운 페이지가 되었습니다.
사용자 권한 관리
금융 관련 시스템은 보통 개인이 본인의 계좌만 다루면 됩니다. 하지만 제가 만들고 있는 시스템의 요구사항은 좀 다릅니다. 주 관리자인 저희 아내가 4명 계좌를 모두 바라볼 수 있어야 하고, 저는 같은 그룹원으로서 자료를 조회할 수 있어야 합니다. 또, 시스템을 관리하기 위한 관리자 권한도 필요합니다.
V3까지는 개인용 도구였고, 그때는 고려하지 않았던 요구사항들이 추가된 겁니다. 누가 무엇을 볼 수 있고, 누가 무엇을 쓰거나 지울 수 있는가입니다. 기능은 그대로지만, 접근 주체가 한 명에서 여럿으로 늘면서 권한과 공유라는 추가 요구사항이 전면에 나옵니다.
여기서 가장 많이 헷갈린 것은 코드보다는 개념, 즉 도메인 모델이었습니다. 바로 사용자와 소유주의 구분입니다.
- 시스템 사용자 — 웹서비스에 로그인해 파일을 올리고 관리하는 사람입니다.
- 계좌 소유주 — 거래 데이터 안의 명의자 분류값입니다.
AI와 대화를 하는 과정에서 AI도 당연히 일반적인 시스템을 고려하고, 사용자와 계좌 소유주를 동일시하고 대화를 하였습니다. 그러다 보니 당연히 엉뚱한 구현이 들어가게 되었고, 한참이 지난 후에, 제가 상황을 깨닫고 이를 정리했습니다.
예를 들어 제가 로그인해 올린 파일 안에 아이 명의의 계좌 거래가 들어 있을 수 있습니다. 이때 업로드한 시스템 사용자는 저이고, 계좌 소유주는 아이입니다. 사용자와 소유주는 다른 것이라는 정의를 분명히 하고 나서야 정리됐습니다.
사실 이건 굉장히 중요한 경험이었습니다. 이후 AI와 대화할때 좀 더 명확하게 상황을 설명하는 습관이 생겼고, 잘 이해했는지 확인이 필요하다는 것도 깨달았습니다. 이는 뒤에서 다룰 협업 방식과도 이어집니다. 사람도 헷갈리는 개념은 AI도 헷갈립니다. 그래서 이 정의를, 프로젝트 안에서 모두가 같은 뜻으로 쓰는 공통 용어로 협업 규칙 문서에 적어 두는 것이 좋습니다.
권한 구조는 실제 사용 흐름에 맞춰 정리했습니다.
- 설정 화면에서는 본인이 올린 데이터만 관리합니다.
- 조회·통계 화면에서는 같은 그룹 사용자의 데이터까지 볼 수 있습니다.
- 관리자는 전체 데이터를 봅니다.
삭제 정책도 바꿨습니다. 처음에는 데이터와 파일을 실제로 지우는 방식이었지만, 여러 사람이 쓰는 환경에서는 위험했습니다. 그래서 일반 사용자의 삭제는 삭제 요청으로 표시만 하고, 실제 완전 삭제는 관리자가 진행합니다. 삭제 요청된 항목은 조회·통계·export 계산에서 제외됩니다. 함께 관리하는 환경에서 실수로 남의 데이터를 지우는 일을 막고, 복구와 감사 가능성을 남기기 위한 선택이었습니다.
개발 및 운영 방식
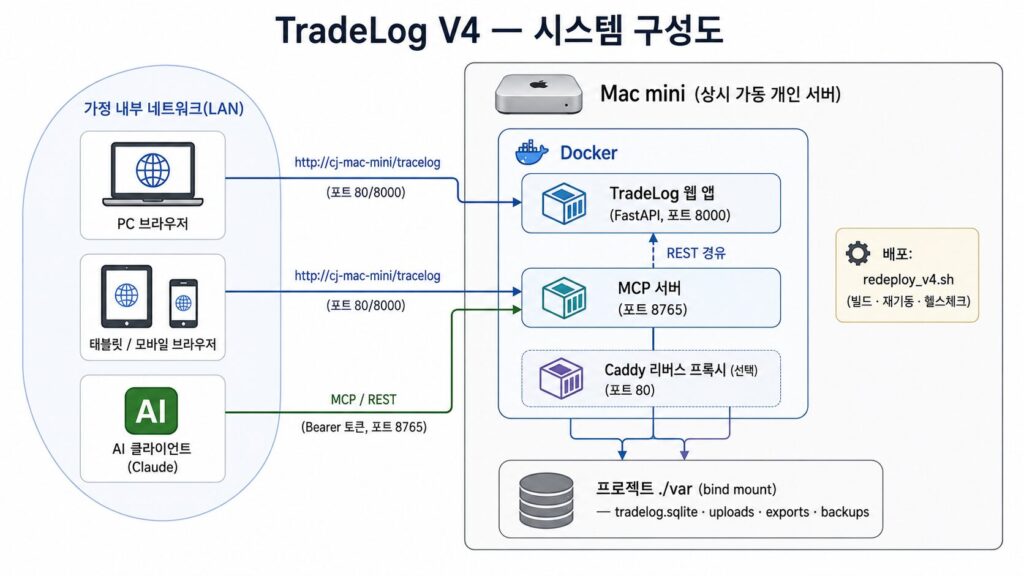
개인이 만드는 웹서비스 개발은 고치고 → 다시 띄우고 → 확인의 반복입니다. 이걸 매번 손으로 하면 느리고, 무엇보다 빼먹기 쉽습니다.
그래서 반복되는 일을 스크립트로 묶었습니다. redeploy_v4.sh 라는 별도의 스크립트를 만들고 이미지 빌드, 컨테이너 재기동, 상태 확인, 헬스 체크까지 한 번에 수행합니다. 이후로는 UI나 API를 고칠 때마다 이 스크립트로 실제 서버 반영까지 확인하는 흐름이 개발 절차에 자리잡았습니다. 1편에서 작은 배포 문제를 겪었던 것의 연장선인데, 반복되는 수동 작업은 일찍 스크립트로 만드는 편이 결국 빠릅니다. 물론, AI를 이용해서 만들었습니다.
운영 데이터는 프로젝트의 ./var 폴더 하나로 모아, 백업과 복구가 단순해지게 했습니다. 정적 파일을 수정할 때 브라우저 캐시에 옛 화면이 남는 문제가 있어, 자산 버전을 함께 올리는 규칙도 정리했습니다.
테스트는 변경의 성격에 따라 범위를 달리하는 하네스로 묶었습니다. 문서만 바뀌면 테스트를 생략하고, 코드나 API가 바뀌면 영향 범위에 맞는 테스트를 우선합니다. DB 스키마나 통계 계산처럼 영향이 넓은 변경에서만 전체 테스트를 돌립니다. 이런 규칙이 있어야 AI가 큰 작업을 한 번에 밀어붙이지 않고, 단계마다 검증하며 진행하게 됩니다.
MCP 도입 — AI가 직접 쓰는 도구
여기까지는 주 사용자를 사람으로 보았습니다. 그런데 한 걸음 더 나아가, AI와 대화를 통해 데이터를 조회하고 분석할 수 있다면 사용성이 더욱 개선될 것 같았습니다. 그래서 회사에서 경험해보았던 MCP(Model Context Protocol)를 적용하기로 했습니다. AI가 직접 이 데이터를 다룰 수 있는 통로를 만들었고, 접근의 폭을 사람 너머로 넓힌 셈입니다.
웹 화면이 쓰는 입력·조회·통계 기능을 문서화된 REST API로 고정하고, 그 위에 토큰 기반 인증을 얹었습니다. Authorization: Bearer <토큰> 방식이고, 토큰에는 소유자·권한 범위·만료 상태를 둡니다. 토큰 원문은 발급 시 한 번만 보여 주고 DB에는 해시만 저장합니다. 권한도 read:transactions, write:uploads처럼 범위를 나눠, 범위 밖 요청은 거부합니다.
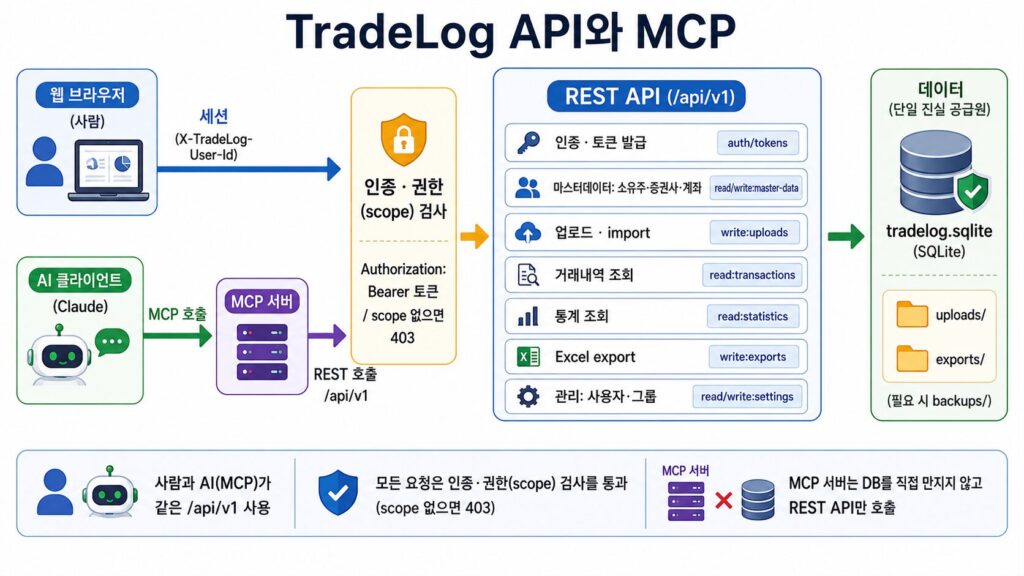
이 API 위에 MCP 서버를 올렸습니다. MCP는 AI가 외부 도구를 표준화된 방식으로 호출하게 해 주는 통로입니다. 핵심은, MCP 서버가 DB나 파일을 직접 만지지 않고 REST API를 거쳐서만 동작하게 한 것입니다. 사람이 쓰든 AI가 쓰든 같은 규칙과 권한을 지나게 됩니다. 실제로 Claude에서 토큰으로 이 서버에 연결해 계좌와 거래를 조회하는 것까지 확인했습니다.
처음에는 AI와 협업해 만든 도구였는데, 이제는 AI가 직접 쓰는 도구로 넓어진 셈입니다.
AI와의 협업 방식
1편에서는 AI와 함께 일하며 남긴 문서들을 정리했습니다. 이번 글에서 달라진 점은, 제가 좀 더 익숙하지 않은 영역으로 들어서면서 협업 방식의 무게중심이 옮겨갔다는 것입니다.
엑셀 자동화까지는 AI가 빠른 손에 가까웠고, 필요하면 제가 직접 따라갈 수 있었습니다. 하지만 백엔드, 데이터베이스, 인증, 배포 운영은 제가 깊이 다뤄 본 영역이 아닙니다. 여기서는 AI가 더 많은 부분을 주도하고, 저는 방향과 기준을 잡는 역할로 옮겨갔습니다.
그럴수록 분명해진 점은, 결과의 품질이 제가 AI에게 준 맥락의 정확도에 많이 기댄다는 것이었습니다. 이번 과정에서 다룬 결정들이 사실 대부분 그 맥락이었습니다. DB가 원본이라는 제품 원칙, 사용자와 소유주는 다르다는 도메인 정의, 엑셀 숫자와 맞아야 한다는 검증 기준. 이것들을 문서로 분명히 남겨 두었기에, AI가 모르는 영역을 주도하면서도 방향이 크게 어긋나지 않았습니다.
설계를 먼저 문서로 합의하고 작은 단위로 구현한 것, 도메인 용어를 협업 규칙에 강조해 둔 것, 검증 기준을 끝까지 유지한 것 모두가 AI에게 정확한 맥락을 주는 일이었다고 볼 수 있습니다.
결국 제가 한 일의 대부분은 코드를 짜는 것이 아니라, 무엇을 왜 만들어야 하는지를 언어로 정확히 규정하는 일이었습니다. 익숙하지 않은 영역일수록, 직접 구현하는 능력보다 요구사항과 제약을 명확히 정의하고 결과를 검증하는 능력이 더 중요해졌습니다. AI가 손이 되어 줄수록, 사람의 일은 방향을 정하고 그 결과가 옳은지 확인하는 쪽으로 옮겨가는 셈입니다.
맺음말
웹서비스로의 전환은 단순히 화면을 웹으로 옮긴 일이 아닙니다. 데이터를 하나의 원본으로 모으고, 그 위에 데이터·화면·사용자·운영을 차례로 쌓고, 마지막에 AI가 직접 쓸 통로까지 연 복잡한 과정이었습니다. V1~V3가 기본적인 자동화를 완성하고, 자료 입력을 유연하게 만들어 주었다면, V4는 접근성과 사용성을 넓힌 단계였다고 볼 수 있습니다.
돌아보면 이 흐름은 이전에 정리했던 「바이브 코딩, 제대로 하는 법 — 10가지 원칙」과 맞닿아 있습니다. 작게 시작해 점진적으로 확장하고, 검증 기준을 잃지 않고, 결정을 기록으로 남기는 것. 익숙하지 않은 영역일수록 이 원칙들이 더 큰 힘이 되어 주었습니다.
이제 다음 글에서는 여기서 한 걸음 더 나아갑니다. 지금까지가 거래를 기록하고 조회하는 단계였다면, 다음은 평가입니다. 외부 시세 서비스와 연동해 평가금액과 수익률을 계산하고, API를 제공하는 서비스라면 데이터를 자동으로 수집하는 데까지 이어 볼 예정입니다.
도구는 바뀌어도, 무엇을 왜 만드는지는 결국 사람이 정합니다.
ChulJoo Kim (김철주)
ckarch.kr
© 2026
is licensed under
CC BY-NC-SA 4.0
![]()
![]()
![]()
![]()