지난 글에서 OpenClaw 설치와 모델 연결, Telegram 연동까지 마쳤습니다.
이후, 메일 자동 정리, 뉴스 크롤링, 노션에 글 저장하기 같은 몇가지 자동화를 구현해 보았습니다. 처음에는 단순히 봇 하나에 모든 일을 다 시키려고 했지만, 막상 작업을 늘려가다 보니 구조화가 필요하다는 판단이 들었습니다. 소프트웨어 설계 원칙 중 하나인 단일 책임 원칙(Single Responsibility Principle, SRP)을 적용했다고 볼 수 있습니다.
이를 포함하여, 첫 OpenClaw 자동화 구축 과정을 정리해 보았습니다.
구축 과정 요약
먼저 전체 흐름부터 정리합니다.
| 시점 | 단계 | 핵심 결정 |
|---|---|---|
| 4/24 | 첫 자동화 시도 | 뉴스 사이트 URL 던짐 → “Notion에 저장하려면?” 자연스럽게 전개 |
| 4/24 | 구조 고민 | “메인 에이전트 두고 Gmail, News 따로 가는 게 좋겠다” |
| 4/25 | Gmail 에이전트 | OAuth 적용 과정에서 여러 시행 착오, 발신자별 카테고리 정의 |
| 4/26 | PA (Personal Assistant) 정의 | “비서 에이전트, PA Agent 만들자” , Orchestrator 등장 |
| 4/26 | Notion DB 설계 | 발행 시각/스크랩 시각 분리, 우선순위와 ID 분리 |
| 4/26 | 첫 스케줄 누락 | “20시에 안 돌았어, 원인 분석해” |
| 4/27 | News 에이전트 재설계 | 엉뚱한 사이트에서 가져오는 사고 → “코드 기반으로 새로 만들자” |
| 4/28 | 출력 포맷 안정화 | “코드 기반 출력으로 바꿔” |
서두에 밝혔다 시피, 처음부터 Orchestrator를 생각한 건 아니었습니다. 봇 하나에 다 시키려다 보니, 일이 늘어나면서 점점 분리하게 된 흐름이었습니다.
전체 구조 — 메인 에이전트 + 전문 에이전트
며칠간의 시행착오 끝에 잡힌 최종 구조는 아래와 같습니다.
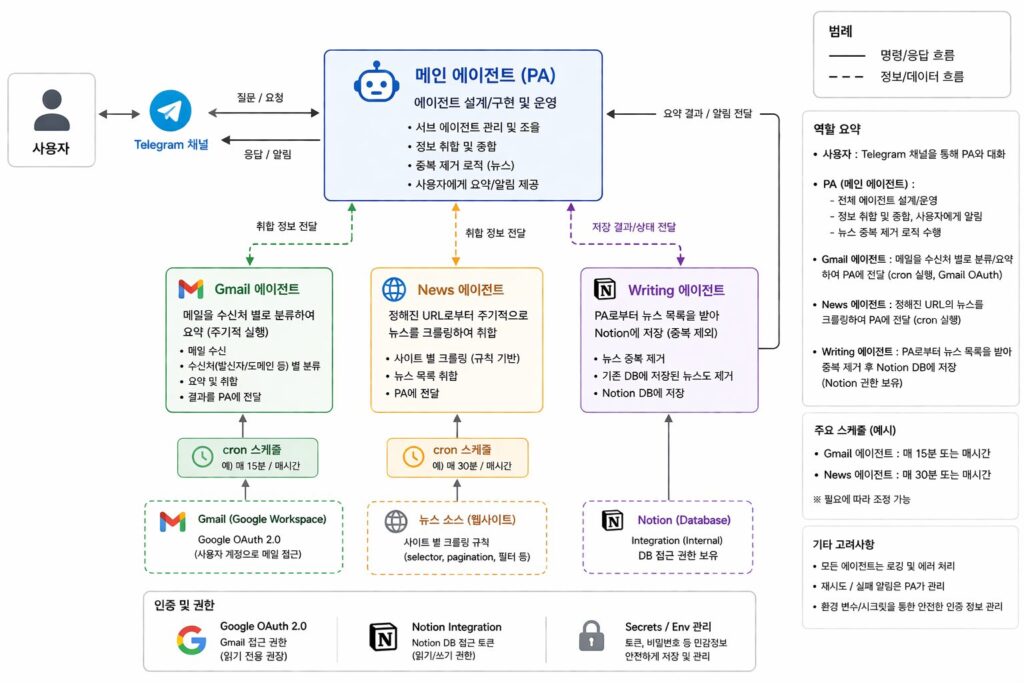
기본적으로 메인 에이전트(PA)를 중심으로 여러 전문 에이전트가 동작하는 Orchestration 구조를 가지고 있습니다.
- 채널: Telegram
- 정보 수집: Gmail, News
- 정보 저장: Notion
- 트리거: cron (주기 실행)
- 제어: PA (메인 에이전트)
주요 흐름은 아래와 같습니다.
- 사용자 → Telegram → PA
- Gmail cron → Gmail → PA → Telegram → 사용자 알림
- News cron → News → PA → Writing → Notion → PA → Telegram → 사용자 알림
가장 중요한 포인트는 메인 에이전트가 Orchestrator 역할을 한다는 점이었고, 그 외 Notion을 단순 저장소가 아닌 데이터베이스로 다뤄, 저장 단계에서 제목+출처 기준으로 중복을 제거한 것도 중요한 결정이었습니다.
메인 에이전트의 정체성
지금부터는 구조 설계 과정에서 헷갈렸거나 고민이 필요했던 부분들을 정리해 보려고 합니다.
제가 가장 헷갈렸던 부분은, “내가 Telegram으로 말 거는 상대가 누구인가” 입니다. 처음에 지어준 CKlaw라는 이름을 부르면 메인 봇이 있어서 모든 일들을 대행해 준다고 막연하게 생각했습니다. 그런데, 막상 메인 에이전트인 PA를 만들고 나니, Telegram 메시지를 보내면 그 일을 CKlaw가 하는 건지, PA가 하는건지 모호했습니다.
결국 이런 질문을 하기에 이르렀죠.
질문: CKlaw와 PA의 관계를 묻는 거야. 지금 Agent들을 만들고 구성하는 일을 CKlaw가 하는 건가?
대답: CKlaw는 OpenClaw 시스템 자체이고, PA는 그 위에서 도는 메인 에이전트입니다. 대화 상대는 PA입니다.
즉, 씨클로는 OpenClaw 자체이고, PA는 그 위에서 도는 메인 에이전트로서 실제 일을 조정하는 주체라는 설명이었죠. 어찌보면 당연한 구분인데, 처음에는 이게 한 덩어리로 느껴졌습니다. 플랫폼과 그 위에 사는 에이전트는 다르다는 점을 명확하게 이해한 게 구조 정리의 출발점이었습니다.
메인 에이전트의 역할: 직접 실행 NO, Orchestrator Only
메인 에이전트인 PA를 만들 때 제일 먼저 정한 건, PA가 하면 안되는 일 이었습니다. 지시를 모호하게 하면, PA가 모든 걸 직접 처리하더군요.
참고로 에이전트를 분리해야 하는 이유는 기능을 단순하게 만드는 목적도 있으나, 그 외 에이전트 별로 모델을 다르게 적용하거나, 동작 시점을 관리하는 등 여러 관리 측면에서도 이점이 있습니다.
실제 사례로, News 에이전트를 테스트하는 과정에서 실행 주체를 명확하게 언급하지 않고 지시를 했더니 갑자기 PA가 직접 뉴스를 크롤링하거나 Notion에 직접 저장하려고 하더라구요. 그래서 아래와 같이 역할을 명시했습니다.
- PA가 하는 일 : 요청 분류, 전문 에이전트 판단, 메시지 전달 및 결과 회수, 사용자에게 최종 요약 보고
- PA가 하지 않는 일 : 직접 정보 수집, 직접 Notion 원본 저장, 직접 메일 처리 로직 수행
권한과 책임이 흩어지는 순간, 테스트도 디버깅도 모두 비싸집니다.
PA는 조정만, 저장은 Writing Agent만 과 같이 각자의 역할을 강제하는 게 결국 가장 안정적이었습니다.
News 에이전트 : “엉뚱한 데서 가져왔네” 사건
가장 많이 손을 본 에이전트가 바로 News 에이전트 입니다.
처음에는 단순히 URL 목록을 던지고 “주요 기사 정리해줘” 라고 시키면 됐습니다. 그런데 며칠 운영하다 보니 제가 지정하지 않은 사이트 에서 기사가 들어와 있었습니다.
상황을 파악해보니, 이전 cron 작업이 실패를 했고, PA가 스스로 판단하여 임의의 사이트에서 뉴스를 스크랩해 온 것이었습니다. 이런 상황은 LLM 기반 에이전트의 흔한 함정이라고 생각됩니다. 명시적으로 하지 말라고 말하지 않으면 알아서 ‘도움이 되겠다 싶은’ 행동을 합니다. 일종의 할루시네이션 이라고 봅니다. 하지만 그건 사용자가 기대한 행동이 아닐 수 있죠.
나 : 뉴스를 내가 정해준 데서 읽어와야지 왜 엉뚱한 데서 가져온 거야? 뭔가 예외 상황이 보이면 바로 보고하도록 해. 이건 최상위 우선순위야.
이 일을 계기로, News 에이전트는 한 번 통째로 다시 만들었습니다.
나: 지금까지 정리된 기능을 바탕으로 코드 기반 News 에이전트 새로 만들어줘.
이전 글에서 다룬 적이 있듯이, 자연어 형태로 저장된 규칙을 LLM이 추론하게 하는 것 보다, 규칙을 구현한 코드를 만들어 실행하는 것이 훨씬 안정적이고 효율적입니다.
Writing Agent : 쓰기 권한은 한 곳에 집중
앞서 언급했듯이 Notion 저장은 Writing 에이전트만 담당하도록 했고, PA나 News 에이전트도 Notion에 직접 쓰지 않습니다. 저장이 필요하면 Writing Agent에 요청하는 구조입니다.
처음에 권한이 흩어졌을 때 사고 추적이 어려웠습니다. 한 번은 같은 뉴스가 두 번 저장되는 일이 있었고, 어디서 중복이 발생했는지 찾는 데 시간을 꽤 썼죠. 권한을 한 곳으로 모으니 중복을 체크하는 일도 한 곳에서 처리가 가능했습니다.
저장된 뉴스를 조회하는 것도 마찬가지입니다. 최신 배치든 특정 시각 배치든, 모든 조회는 Writing Agent를 거치도록 했습니다.
Gmail Agent : OAuth 삽질과 카테고리 분리
Gmail 에이전트는 OAuth 권한을 주는 단계에서부터 여러 번의 시행착오가 있었습니다. 제 작업 PC에 여러 Google 계정이 로그인 되어 있다보니, 특정 계정 권한을 가져오는 과정에서 redirect_uri 오류, 다른 계정으로 로그인되는 문제, 토큰 만료 등으로 시간을 좀 허비했습니다.
해결한 후, 메일 분류는 발신자 기준 으로 잡았습니다.
- 뉴스레터:
lee@lou2.kr,news@hada.io,miraklelab@mk.co.kr,marketing@skdt.co.kr - 블로그 알림:
wordpress@ckarch.kr - 구직 정보:
jobalerts-noreply@linkedin.com,career-notification@rememberapp.co.kr
처음에 별도의 가이드를 주지 않았더니 하나의 메시지에 모든 정보를 보내주더군요. 또, 몇 번의 대화 끝에 카테고리 별로 메시지로 분리하고, 각 카테고리에 맞는 포맷을 지정하기로 했죠. 메시지를 분리하고 나니 훨씬 읽기 편해졌습니다. 확인 → 분류 → 요약 → 포맷팅 각 단계를 분리해 둔 게 이런 변경을 쉽게 만들었습니다.
메시지 포맷 설정
메시지 포맷은 사실 호불호, 또는 선호도의 문제라서 쉽게 만족하기가 어렵습니다. 또 샘플을 만들어 주고 똑같이 해달라고 해도 매번 조금씩 다르게 나오더라구요. 어떤 날은 “요약:” 이라고 붙이고, 어떤 날은 그냥 줄바꿈 후에 내용만 나옵니다.
여기서도 같은 결론이었습니다. 결정적인 출력은 자연어 규칙이 아니라 코드로 박는다.
나: “요약” “태그” “링크” 이런 말은 제외하고, 메시지 출력 부분을 규칙 대신 코드로 바꾸자.
현재 메시지의 형태는 아래와 같습니다.
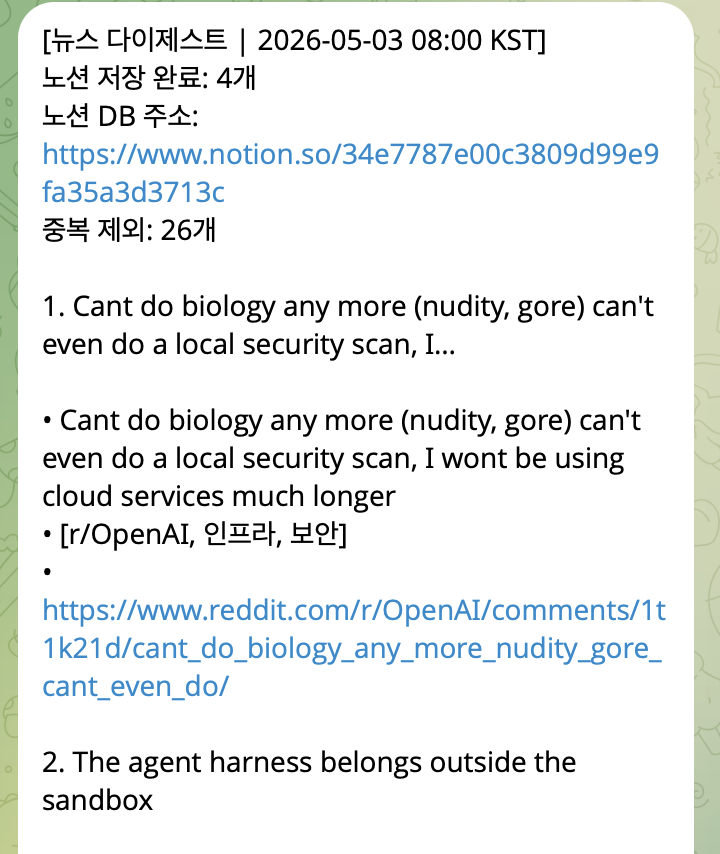
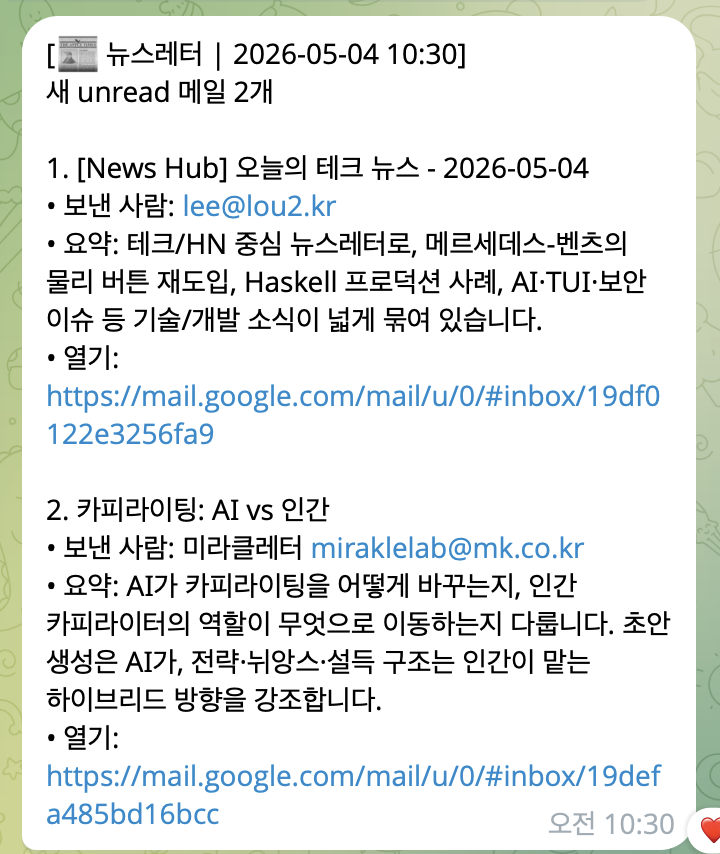
당연히 자연어 규칙보다 코드가 훨씬 일관된 형태의 메시지를 만들어 줍니다.
사소해 보이지만, 매일 6~8번씩 Telegram으로 받아 보는 메시지의 가독성이 사용 만족도에 큰 영향을 줍니다.
현재 버전도 아주 만족스럽지는 않지만, 적응 중입니다.
에이전트 간 메시지 규칙
에이전트끼리는 어떻게 통신을 해야 하는가? 이것도 처음에 한 번 막힌 부분이었습니다. 처음에는 막연하게 Telegram을 거쳐서 메시지를 주고 받게 할까도 고민했지만 그건 사용성에서 말이 안됩니다. 결국 에이전트 간에 직접 통신하는 구조로 가되, 타입을 명확히 나눈 JSON 으로 인터페이스를 통일했습니다.
현재 사용 중인 타입은 세 가지입니다.
news_digest— News Agent가 PA에 뉴스 묶음을 전달news_save_request— PA가 Writing Agent에 저장을 요청save_result— Writing Agent가 저장 결과를 회신
예를 들어 저장 결과 메시지는 이런 형태입니다.
{
"type": "save_result",
"run_id": "2026-04-26T16:12:00+09:00",
"destination_key": "news_scrap",
"saved_count": 20,
"failed_count": 0,
"notion": { "database_url": "...", "page_urls": [...] }
}
이렇게 타입을 나누고 나니, 에이전트가 서로를 추측하지 않고 통신할 수 있게 되었습니다. 한쪽이 바뀌어도 다른 쪽이 흔들리지 않습니다. 인터페이스(Interface)가 정의된 거죠.
스케줄링: 허위 보고 사건
뉴스 자동 실행 시간은 08시, 13시, 20시로 하루 3회로 잡았습니다.
그런데, 설정한 첫날, 20시가 지났는데 아무 메시지가 오지 않았습니다.
나: 20시 지났는데? … 20시에 뉴스 스크랩이 안 돌았어. 원인 분석해.
원인은 단순했습니다. PA가 Agent 설정에만 반영을 하고, 실제 cron 작업 생성은 안했습니다.
이 경험에서 확인한 게 있습니다. 가짜 보고에 속으면 안된다는 것입니다. 항상 End-to-end로 확인하는 습관이 중요합니다.
에이전트 설계/운영 원칙 5가지
지금까지 제가 경험한 시행착오를 통해 알게 된 원칙입니다. 흥미롭게도 거의 모두 전통적인 소프트웨어 설계 원칙과 맞닿아 있습니다. Agent 시대라고 해서 아주 새로운 원칙이 필요한 건 아닙니다.
1. Do와 Don’t를 모두 명시하라 : 하는 일만 적지 말고 하지 않는 일도 명시할 것. 정확한 명세(Specification)이 중요함.
2. 역할은 하나, 인터페이스는 명시적으로 : 한 Agent에 한 가지 책임만 부여, Agent 간 통신은 명시적 인터페이스 정의.
3. 결정적인 출력은 코드로 박아라 : LLM은 자연어 처리 중심으로, 명확한 작업은 코드 기반으로 설계할 것.
4. 가짜 보고에 속지 말고 End-to-End로 검증하라 : 에이전트의 보고를 다 믿으면 안됨. End-to-End 검증이 중요.
5. 예외는 숨기지 말고 드러내라 : 모든 것을 기록하고 명시되지 않은 행동은 보고하도록 할 것.
정리하고 보니 결국 이 규칙들은 모두 최근 큰 관심을 가지고 있는 하네스 엔지니어링 – LLM을 둘러싼 시스템 프롬프트, 인터페이스, 검증 로직 같은 껍데기를 설계하는 일 – 에 맞닿아 있다는 생각이 듭니다.
제 이전 글 ‘AI시대: 코딩은 진화 중, 사라지지 않는다.’ 에서도 하네스에 대해 언급한 적이 있습니다. 결국 비결정적으로 동작하는 AI에이전트를 예측가능하고 안전하게 돌릴수 있는 규칙을 만들고 환경을 구축하는 일이 바로 핵심이 될 것입니다.
향후 계획 및 느낀점
지난 글 끝에 OpenClaw가 정말 만능 도구인지, 아직은 전문가의 손길이 필요한 도구인지 확인해 보겠다고 적었습니다.
솔직한 저의 느낌은 아직은 중간 입니다.
대화 한두 번으로 봇이 알아서 모든 걸 해주는 수준은 아니었습니다.
작업이 두세 개만 늘어도 역할, 권한, 인터페이스, 저장 규칙을 분리 해 줘야 안정적으로 굴러갑니다.
그리고 그 분리는 결국 사람이 설계해 줘야 합니다.
인터넷의 많은 OpenClaw 글이 결과만 보여줍니다.
그러나 그 결과에 도달하기까지, 예상보다는 험난했던 시행착오 과정이 필요했습니다.
단, 앞 단락에서 언급했듯이, 에이전트를 다루는 일이 전통적인 소프트웨어를 다루는 일과 크게 다르지 않다는 점입니다.
어쩌면 그게 바로 AI와 함께하는 코딩이 되지 않을까 싶습니다.
만능 도구는 아직 없지만, 우리가 믿고 신뢰할 만한 시스템은 만들 수 있습니다.
ChulJoo Kim (김철주).
ckarch.kr
© 2026
is licensed under
CC BY-NC-SA 4.0
![]()
![]()
![]()
![]()